Ever since Intel’s Hyper-Threading and AMD’s Bulldozer modules, there has been much debate on what qualifies as a real CPU “core”. Unfortunately, I don’t think “core” is easy to define, so marketing tends to name things for their own benefit. In the end, it’s the performance that matters, not the name.
What is a “core”?
It used to be simple to define “core”: Fetch, decode, ALUs, cache, attached over a memory bus of some sort, executing a single thread. Multiprocessor systems would replicate this on a board (SMP), package (MCM), or die (CMP). However, when considering two threads, there is a continuum of design points that range from time-slicing threads on an unmodified CPU core (1.0× throughput) to two full cores with all hardware replicated (>1.9× throughput on two CPU-bound tasks). The two extreme points are traditionally called “one core” and “two cores”, but we now have to come up with names for intermediate design points where only some hardware is replicated to service two hardware thread contexts.
Thus, marketing chooses whatever term suits their interests. GPU manufacturers also abuse the words “core” and “processor” to describe something more similar to an ALU or execution unit (Nvidia: “Streaming processor” or “Cuda Core”; AMD: “Stream processor”; but not Intel).
A Performance Metric
The essential characteristic of having two threads is that the software developer must parallelize a task into two mostly-independent threads (this is a hard problem!), and the system will “consume” this two-way parallelism and turn that into some amount of performance improvement (from ~1× for time-slicing a “single-core” to 2× for a perfect “dual-core”), at some hardware cost (from 1× for time-slicing to somewhat over 2× for two cores with interconnect). I will ignore the issue of hardware cost, as higher performance usually implies a higher cost and whether this trade-off is “good” is far too complicated to have a single answer.
This performance metric is quite easy to measure, and answers the question: If I gave the system two independent threads rather than one, how much performance will it give me in return for my effort? We are already familiar with the two extreme points of this design space: 1.0 is called “single core”, and near-2.0 is called “dual core”. Both Intel Hyper-Threading and AMD’s “modules” lie somewhere in between.
Methodology
All of the above really just boils down to re-running my earlier Hyper-Threading Performance tests again on AMD systems. This involved taking some workloads, running multiple independent instance of it, and measuring total throughput as the number of parallel instances increase. The workloads use very little floating-point, avoiding a bottleneck on AMD chips caused by not having replicated FPUs within a module.
I tested four microarchitectures:
| Intel Lynnfield | Core i7-860, 3300 MHz |
|---|---|
| Intel Ivy Bridge | Core i7-3770K, 3900 MHz |
| AMD Bulldozer | FX-8120, 3400 MHz |
| AMD Piledriver | FX-8320, 3400 MHz |
Results
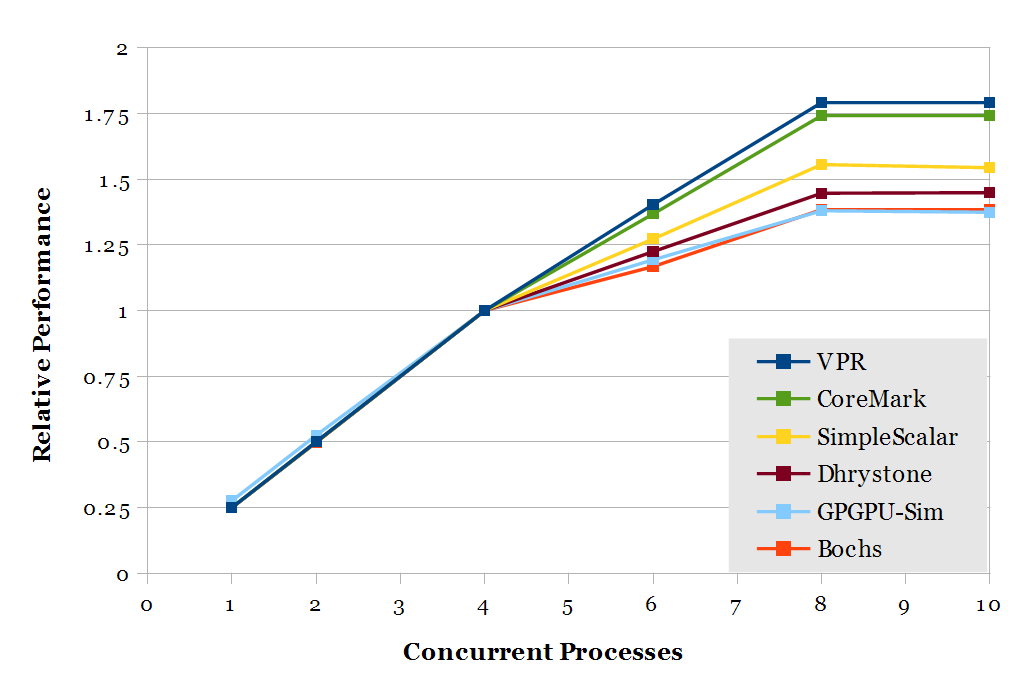
AMD FX-8320 (Piledriver) throughput scaling
This plot shows how throughput scales as more instances of a workload are run concurrently on an AMD FX-8320, normalized to four threads. There is linear scaling until a clear bend in the curve at 4 threads, which indicates that using two threads in a module does not perform as well as two full cores. Running two threads per module results in 38-79% increased throughput (geomean 54%). Throughput does not increase beyond 8 threads because the OS is time-slicing threads onto 8 hardware thread contexts, and time-slicing offers no performance improvement to CPU-bound tasks.
The following two graphs compare the throughput of 8 vs. 4 threads (ideal speedup = 2), and 4 vs. 1 thread (ideal speedup = 4), respectively.
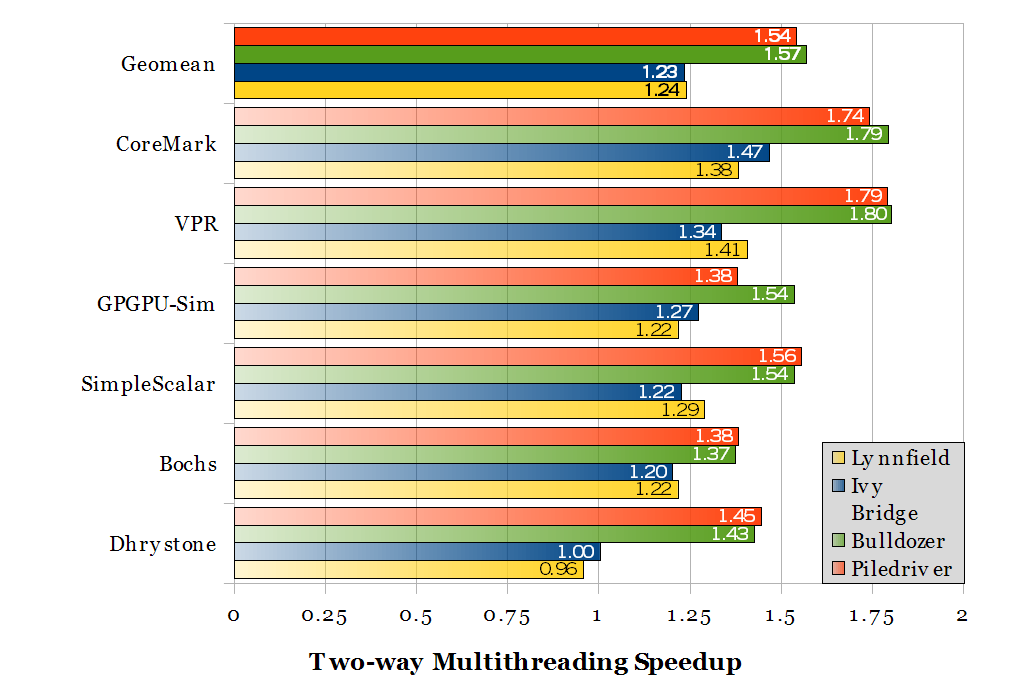
Speedup from two-way multithreading, comparing 8 threads to 4. Ideal speedup is 2 for replicated CPU cores.
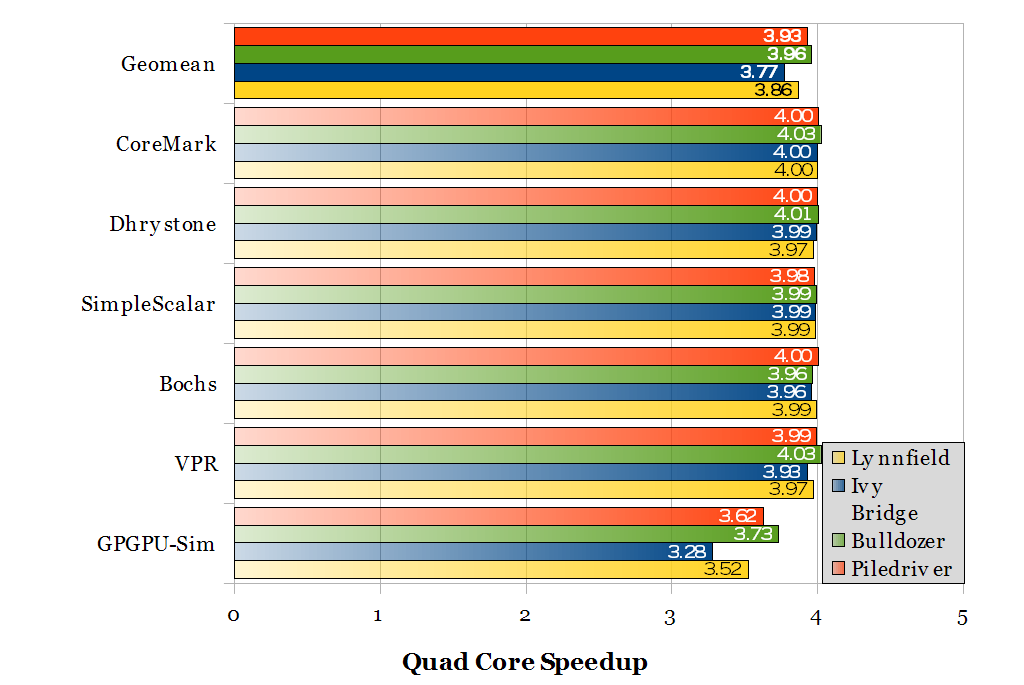
Speedup from four cores (with shared last-level cache). Ideal speedup is 4.
The two-way multithreading speedup shows that AMD’s greater replication of hardware within a module results in greater performance improvement (1.54-1.57) compared to Intel’s minimal hardware replication for Hyper-Threading (1.23-1.24). In my opinion, neither of these are close enough to 1.9-2.0 to deserve being called a “core”. However, the two-thread performance gains are sufficiently higher than Intel’s that it wouldn’t be entirely fair to say “it’s just Hyper-Threading” either.
The quad core speedups show that “real” cores actually do scale very close to ideal for most workloads, at least for up to four cores.
Moot point?
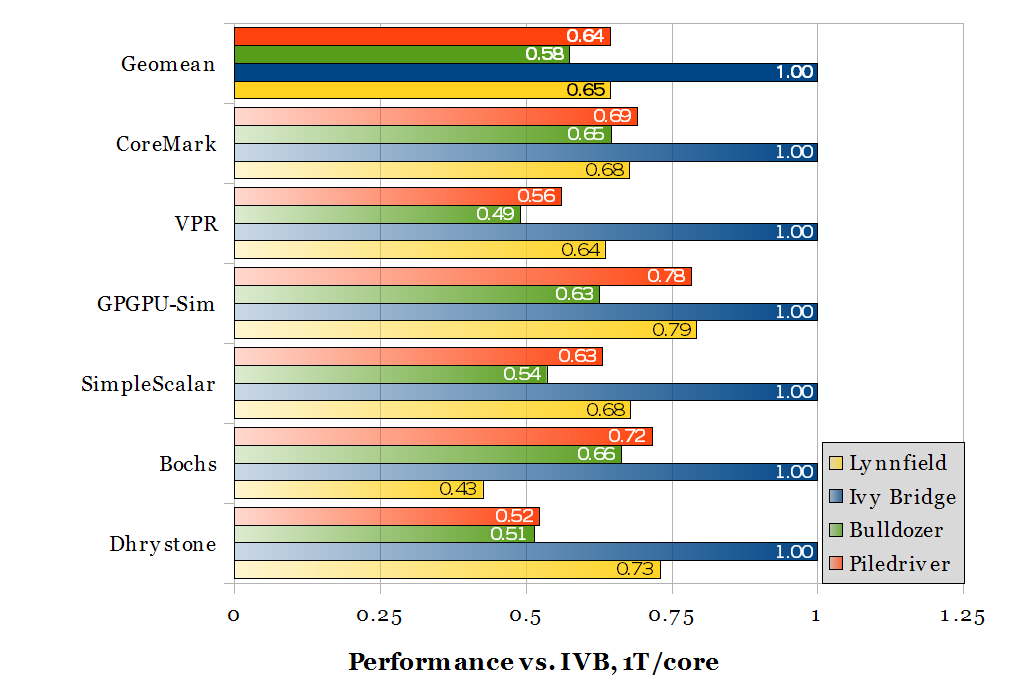
Performance relative to 3.9 GHz Ivy Bridge, one thread per core
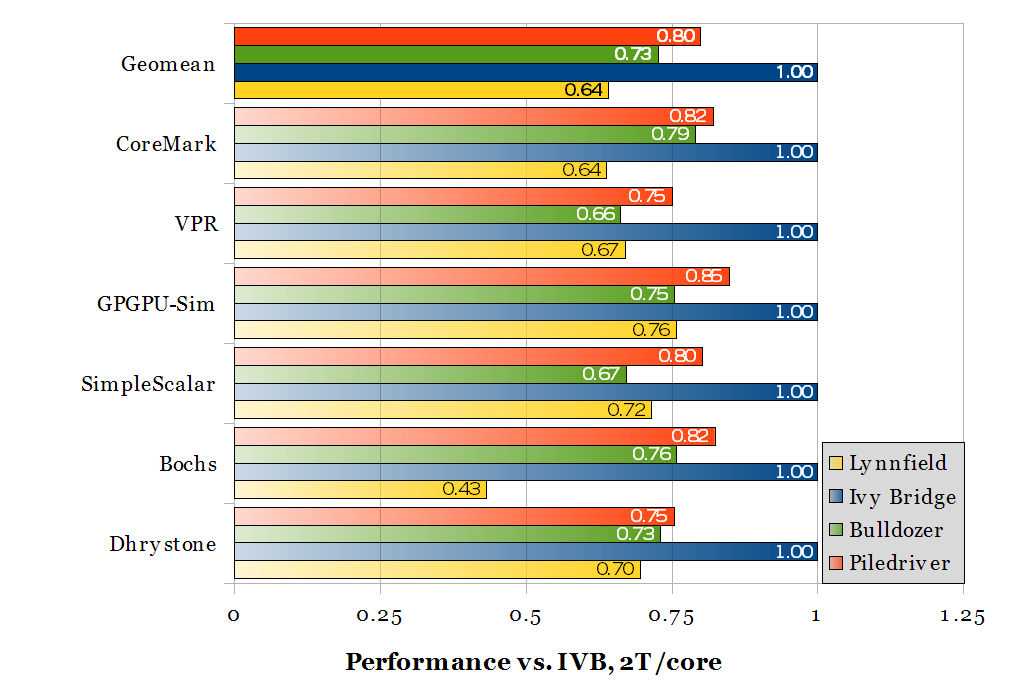
Performance relative to 3.9 GHz Ivy Bridge, two threads per core
But all of this may be a moot point. In a thermally-constrained environment (densely-packed cardboard boxes) where the high power consumption of an AMD chip causes it to lose its clock speed advantage over Intel, the AMD chips perform rather poorly regardless of how many threads are available. As configured (see above table), the AMD chips already consume more power.
Conclusions
In summary:
| Single core | 1.0 |
|---|---|
| Hyper-Threading | 1.23 |
| Piledriver Module | 1.54 |
| Dual core | 1.9-2.0 |
AMD’s marketing department did a good job convincing most of the world that a thread context that delivers only 54% more throughput deserves to be called a “core”.
I believe you may have inadvertently included turbo-scaling losses in with your calculations for CMT scaling losses.
No, turbo is disabled, and clock speed is set to a fixed 3.4 GHz. 3.4 GHz isn’t the stock clock speed for either of the two AMD processors.
If Turbo really was enabled, you would see a bend in the curve between 1 and 4 threads, rather than linear scaling.
We have found different results on a trivial floating point test:
“Hyperthreading increases performance by 16% whereas AMD’s core duplication increases performance by 67%. On the other hand we see that Intel’s 2.4GHZ processor performs the same single-thread 24 operations per second that AMD’s 3.2GHZ processor is capable of.”
So we would have:
Intel HP 1.16
AMD 1.67
http://blog.angulosolido.pt/2014/01/core-confusion.html
We focused on a simple floating point test because a customer needs to run parallel floating point calculations. Plus we weren’t aware of “AMD chips not having replicated FPUs within a module” as you stated in the article, but what we found doesn’t seem to agree on this.
Yep, performance scaling with SMT is dependent on the workload. Even in my results, the range is quite big (1.4-1.8 for AMD, 1.0-1.5 for Intel). It wouldn’t be difficult to create a microbenchmark that gets ~2.0 for both.
What benchmark are you running, and which part of the processor is the bottleneck? I wouldn’t be surprised if a shared FPU still isn’t a bottleneck. Depending on the algorithm, it could be limited by branch mispredictions, memory latency, or even FPU latency (if there isn’t enough instruction-level parallelism to fully utilize the relatively high-latency FPU).
We are using this simple script:
http://pastebin.com/PKSCJV1R
I don’t claim that this is representative of any particular workload. It is clearly too simplistic for that, but good enough to push CPU usage to the limit.
What we got is not shockingly different from what you got. I was a bit surprised about the shared FPU thing that I didn’t know about, and also about how AMD had worst single thread performance per GHZ.
—————
Single core 1.0
Intel Hyper-Threading 1.16
AMD Module 1.67
Dual core 1.9-2.0
The workload you’re using doesn’t use any floating-point… It runs
bc, which is an arbitrary-precision calculator that uses only integer instructions.And yeah, AMD has been lagging behind in IPC (instructions per cycle) ever since Core 2 in 2006, and that gap has been growing since. That explains their current financial situation…
Hi Henry,
Your blog doesn’t notify about new comments, does it?
I know we are running bc. But you say it does all the internal calculations, including operations with fractions, with integers? Interesting, I wasn’t expecting that.
Are you aware of a cli utility that can perform the same operation using FP? I’d like to update our post and compare the results.
Regarding AMD vs Intel, I woudn’t jump into that conclusion so fast. Look at this cost comparison for machines for similar price:
1)
AMD two proc x 4 core 2.8 GHZ machine = 2708 EUR
Total guaranteed GHZ: 2 x 4 x 2.8 = 22.4
Thread scaled GHZ: = 22.4 x 1.66 = 37.2
2)
Intel two proc x 6 core 2.1 GHZ machine = 2890 EUR
Total guaranteed GHZ: 2 x 6 x 2.1 = 25.2
Thread scaled GHZ: = 22.4 x 1.66 = 37.4
Cost per guaranteed GHZ:
AMD: 2708 / 22.4 = 120.9 EUR
Intel: 2890 / 25.2 = 115.6 EUR
Cost per thread scaled GHZ:
AMD: 2708 / (22.4*1.67) = 72.4
Intel: 2890 / (25.2*1.16) = 98,8 EUR
I have no idea how WordPress comment notifications work 🙁
Yes, bc uses only integer instructions. I even ran it through an x86 simulator to be certain 🙂
I think you’d want to write your own in C, and probably something more realistic (data dependencies, branches, and memory accesses matter more than the arithmetic). Maybe looking for a ~standard benchmark makes more sense. The calculation you’re running (2.01^(2^13)) is really just one call to the
pow()routine in the math library, which takes < 50ns at 4.2 GHz (Ivy Bridge).Yes, AMD has to lower the price, or it won’t sell anything at all… The AMD chips are more expensive to produce (~315 mm2 for Piledriver 4-module vs. ~246 mm2 for 6-core Ivy Bridge).
Power consumption is higher for AMD (affects both electricity costs and density), especially at higher clock frequencies. There are also users who want shorter job runtimes (and will disable SMT), and also jobs with high memory usage (can’t run many instances in parallel).
AMD’s current chips make most sense only if power is not a concern, your jobs don’t use much memory, and you care only about throughput and not job duration.
Dual-socket systems don’t make much sense to me, unless you really need shared memory between all the cores:
Intel 4-core 3.4 GHz (Core i5-3570k) machine = ~$500 CAD
Total guaranteed GHz = 1 * 4 * 3.4 = 13.6 (No SMT)
Cost per GHz: $600/13.6 = $44 (31 EUR)
Overclocked (4.2 GHz, ~130W at the wall): $35/GHz (25 EUR/GHz)
Hi again Henry,
I realized that comparing prices per GHZ makes no sense since we have seen that the number of operations per GHZ depends heavily on the processor.
We should compare the number of operations per GHZ and develop a “brand factor” that enables the comparison between processors from Intel and AMD with different clock frequencies.
And we should compare the number of operations per invested EUR 🙂
Of course all this depends on the workflow.
Furthermore I replaced bc with wcalc on my script. Now I know it is working with floating point because I needed to increase the exponent a lot for each calculation to take a measurable amount of time.
Surprisingly AMD’s single thread per GHZ performance became better than Intel’s and and double thread scalability become perfect. This doesn’t seem to agree with what you said about shared FPU between AMD’s two sibbling threads, does it?
The summary is here:
http://blog.angulosolido.pt/2014/10/core-confusion-round-ii.html
wcalc is also an integer workload. I measured about 0.6% floating-point instructions. If it was really floating-point, the runtime would (approximately) not depend on the size of the numbers. One possible implementation is to use FYL2X and F2XM1 (take logarithm and multiply, then anti-log). It wouldn’t involve a loop, as you seem to be expecting. (Hint: “arbitrary precision” calculators are likely integer, because floating-point has fixed precision. x87 uses 80-bit floats.)
I think your timing script also has some timing precision issues.
timereports runtime in units of 0.01 seconds, and your runtimes are so short that rounding error is huge. For example, on my Ivy Bridge 4.2 GHz, your script says “100” ops/s (because every run takes “0.01” seconds), and Piledriver 3.5 GHz is “50” ops/s, with each run taking “0.02” seconds.I think you really need a better benchmark, preferably with the task that will actually be used. If you don’t know what the users will be running, perhaps you might be interested in published results for SPECfp?
http://www.spec.org/cpu2006/results/rfp2006.html
And of course, we second your feelings about AMD’s marketing.
If that’s so then wcalc is a muuuchh faster integer implementation! And what do we need FPUs for then? I guess AMD was right in not duplicating the FPU inside their cores 🙂 I’m kidding, but anyway, I shall compare the result from pow() + GCC.
Regarding the rounding: you can easily evaluate the importance of rounding by increasing the exponent by a unit (lowers the ops per second to around 8) and calculate the ops per second without rounding. The difference in scalability is not large.
I will update the post.
Regarding better benchmarks: sure we need that to. I wish someone could automate a multiuser terminal server benchmark 🙂
bc and wcalc are different algorithms that don’t solve the same problem, especially with the wcalc -P6 flag (bc seems to keep exact precision, wcalc -P6 keeps 6 digits). Even with -P19872, the two results diverge after the 304th significant digit of 2.01^216. (I don’t know which one is more correct, however).
If you’re going to run
pow()in a loop, be careful you’re not limited by function call overhead. Thepow()function looks a little longer than it needs to be (maybe error and corner case handling?)I do think AMD made a sane and calculated decision to not replicate the FPU. Many server tasks don’t use the FPU. Many HPC tasks use the FPU (simulations of physical things on a grid, for example), but not all do (simulations of CPU microarchitectures like I do, doesn’t).
I think you should try asking your users what tasks they care about. I’m sure if they cared about how fast their jobs ran, they’d be happy to provide a benchmark…
Benchmarking
powdoesn’t have much meaning for real algorithms. Even old benchmarks like Whetstone or the Livermore Loops are often treated with suspicion. If you really don’t know what your users use the computers for, you might also consider LINPACK (TOP500 uses this), fbench or ffbench, or you can look up results for SPECfp. There is no shortage of benchmarks, the hard part is figuring out which one is most representative of what you care about. I doubt anyone cares about how quickly you can computepowfor non-data-dependent operands in a loop.I updated the post again, and this is how far I want to go with the topic right now:
http://blog.angulosolido.pt/2014/10/core-confusion-round-ii.html
Your comments about powl are valid but any benchmark can be criticized except one’s real workload. I used a combination of powl, sqrtl and logl which are common functions in physics simulations. And AMD underperformed significantly but not only on scability (where you mentioned that shared FPU could be a reason) but also in throughput per single threaded GHZ.
On the other hand AMD delivers 32% more per GHZ and 25% more per EUR than Intel, according the the floating point test results from spec.org.
IMO, the most important thing to retain from this discussion is that we really must focus on calculating TPE (throughput per EUR) values and stop caring about announced GHZ and announced number of cores.
i have benchmarked pigz (parallel gzip) algorithm. since each thread uses only 512 kb, it runs entirely inside L3 cache, so me measure “typical” integer workload. according to my tests, HT efficiency was greatly impoved with each cpu generation – it was 20% on mehalem, 40% on sandy bridge and 50% on haswell (this numbers means that 8 threads runs 20%-50% faster than 4 threads on 4-core HT-enabled cpu)
The graphs of “Moot point?” chapter are made with conditions described at “Methodology” chapter?
Intel Lynnfield Core i7-860, 3300 MHz
Intel Ivy Bridge Core i7-3770K, 3900 MHz
AMD Bulldozer FX-8120, 3400 MHz
AMD Piledriver FX-8320, 3400 MHz
While the stock freqency/TDP of Corei7-3770K is 3500MHz/77Watt, the freqency at conditions above is 3900MHz.
This over-clocking should demand more TDP from Corei7-3770K.
So, I’m wondering that Corei7-3770K should also lose performance at thermally-constrained environment, same as AMD FX-XXXX too.
Maybe I must be surprised you run Intel cpus at 100-105°C, while do AMD at 70°C.
http://blog.stuffedcow.net/2014/01/more-cardboard-boxes/
According to
http://www.cpu-world.com/CPUs/Core_i5/Intel-Core i5-3570K.html
i5-3570K should not live above 67.4°C.
Yes, they’re made using those (overclocked) conditions.
Yes, the actual power when overclocked is different from the rated TDP. Because I’m power-constrained, I used a power meter to measure real power after overclocking, and the 4x AMD systems still used more power (640 W total) even when Intel was overclocked (515 W), as you can see from the “More cardboard boxes” post. The “thermally-constrained environment” is ~600W in a box.
Yeah, I run the processors up until close to thermal throttling. They’ve been ok so far. The specification isn’t measuring the same thing: 67.4°C is Tcase (which can’t be measured), while 100°C is die temperature (measured with on-die sensor).