Since the recent (Jan. 2018) disclosure of the Meltdown vulnerability (also called “Rogue data cache load”) [1, 2], there has been a lot of interest, speculation, and hysteria. But a good understanding of the processor microarchitecture feature responsible for it doesn’t seem to be commonly known. This Stack Exchange answer by Peter Cordes is a rare exception, and it actually mentions nearly all of the ideas in this article.
An understanding of the root cause of the vulnerability is important for understanding why only some microarchitectures are affected, the severity (when does it work?) and the potential for fixing it (what hardware needs to change?). Understanding the root cause also allows one to reliably test for the existence (or, even harder, the non-existence) of the vulnerability on various processors, instead of relying solely on vendor self-reporting (or worse, speculation…).
This article first defines the microarchitectural mechanism that allows Meltdown to work, then develops a microbenchmark to specifically test for this behaviour on multiple microarchitectures. This article differs somewhat from security-oriented research. While security research aims to show whether information can be leaked across privilege levels, this article aims to characterize the microarchitectural feature behind it.
Background
This article assumes that the reader understands how pipelined microprocessors work, but I’ll start with a quick review of the important concepts.
CPU Microarchitecture
- Programs are sequences of instructions that are executed in the order they’re written
- A processor must therefore execute the instructions in the order they’re written
- … or at least appear to. It may do anything else (such as out-of-order execution) as long as the result is the same.
Modern (and not-so-modern) processors do not execute instructions one at a time, but work on the instructions in an assembly-line fashion (“pipelined”). This pipelined operation is made possible by separating the instruction execute phase from commit. Execute computes the result of the instruction, and commit makes the result permanent. This allows execution more flexibility to improve performance (can execute speculatively past branches or exceptions, or execute in any order), while the commit stage is responsible for committing the results in the original program order and discarding any operation that should not have been done.
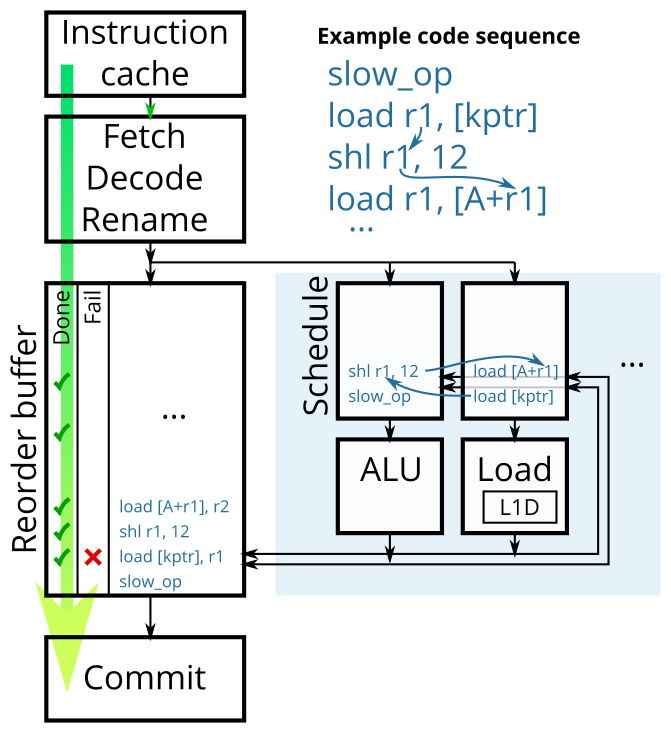
Figure 1 shows a simplified diagram of a typical out-of-order processor microarchitecture. Instructions flow in-order from fetch all the way to commit (green arrow). After register renaming, instructions are placed in an in-order list (reorder buffer) and sent off to the scheduler and execution units with the directive, “Execute these instructions as soon as you can, and tell the reorder buffer when you’re done.” The commit unit then commits the completed instructions in their original order by dequeueing the reorder buffer.
If something bad is detected during execution (exception or branch misprediction), this status is marked in the reorder buffer. If the exception turns out to be real (there wasn’t an earlier exception or misspeculation), then it is handled when the instruction commits.
Handling memory exceptions
Let’s consider what happens with one specific case in a typical out-of-order processor with separate execute and commit phases. Suppose there is a user-mode load instruction that accesses a supervisor-only memory page. When this load is executed, the permission violation will be detected, and a status bit will be set in the reorder buffer to indicate a page fault. If this load commits, the pipeline will be flushed and the exception will be handled. Any processor that has any hope of executing code correctly will do all of this correctly.
But other than flagging a page fault, what else does the load do? It doesn’t matter, because the load will be discarded anyway. Thus, processor microarchitects have at least several valid options. First, does the load behave as though it completed and produced a result (so instructions dependent on it may execute)? Or does it refuse to produce a result (as though it takes an infinitely long time to execute)? If the processor chooses to produce a result, is the result zero, random, or the value read from the L1 cache?
Although the ultimate result is the same (a discarded load and a page fault), it is possible to detect which option the processor chose, and if the load produced a result, it is possible to detect what that value is. One way this can be done is by attempting to use the load result (if any) to perform a second load, and then measuring cache access times to find out which cache line was fetched by the second load, if any.
What is Meltdown?
Meltdown results from the specific combination of microarchitecture design choices where the processor, for a load that fails a permission check, chooses to return a result, and that result value is something not normally accessible from user mode (e.g., the value read out from the L1 cache). Because it is possible to detect the eventually-discarded value of a load (via a cache side channel), privileged information is leaked if the load unit returns a value that came from privileged memory.
Notice that this definition does not require that the processor be capable of out-of-order execution. An in-order processor whose load execution unit satisfies this definition and has enough pipeline stages between execution and commit (to allow for a second speculative load to occur) can potentially have the same vulnerability. However, out of the in-order processors I have tested, none have been able to do enough speculative load cache misses to leak data.
There is some uncertainty about whether the definition of “Meltdown” refers specifically to this specific mechanism, or whether it also includes other potential vulnerabilities that share the same symptoms (reveal some kind of privileged information) and share the same prevention method (removing kernel space page mappings when running in user mode) but caused by an unrelated mechanism. Because I’m focusing on the microarchitectural mechanisms in this article, I will use the narrower definition.
Methodology
I created a microbenchmark that performs a load, then observes how the processor handles it (whether a value is returned, and what that value is). The basic approach is similar to existing Meltdown code, but is designed to identify the behaviour of the microarchitecture rather than with the aim of reading the most data in the shortest time.
My microbenchmark begins by allocating one memory page, then creates two virtual address aliases pointing to it. This means that the same memory is accessible via two different virtual addresses. One of the virtual pages (which we’ll call the “setup” pointer) is set to allow access from user mode. It is used to initially place the memory value into the desired location (prefetched into a cache, or flushed out of the caches) and to observe whether the placement of the data changed after the test. The second virtual page (“test” pointer) is set to varying permissions and memory type settings, then used to perform a load. The microbenchmark uses the setup pointer to set up the initial conditions of the test, performs a (possibly-forbidden) load using the test pointer, then observes the outcome of the load.
# Setup phase: clflush [setup] clflush all of the other memory we touch prefetch [setup] # Optional, if we want to test cached behaviour # Test phase: call specpoline_to_measurements mov eax, [test] # Try to read from possibly-forbidden [test] mov ecx, [sense_array+eax] # Use the load result as an address and eax, 0 # Make eax 0, but don't break the dependency (avoid xor, sub, and mov 0) mov ecx, [sense2+eax] # Detect whether a value was returned by loading [sense2+0] mov ecx, [sense3] # Detect whether this code executed at all 1: jmp 1b # Stop here and wait for pipeline flush # Measurements: JUMP_TO_HERE: Measure load latency to determine whether value is cached, and in which cache: - sense_array, to determine the returned value - sense2, to detect whether the load returned any value - sense3, to detect whether the test code executed - setup pointer, to see if the data was cached or evicted - Done. # Specpoline = Speculative trampoline specpoline_to_measurements: # Insert a few long latency operations here mov [rsp], JUMP_TO_HERE ret # Speculatively jumps to test phase code, then non-speculatively jumps to measurements.
The core of my microbenchmark is illustrated (simplified) in Figure 2. The setup phase flushes the relevant cache lines, then places the memory value under test in the desired location in the memory hierarchy (L1, L2, or memory). The test phase is then executed speculatively. The measurement phase then executes after the test phase has completed.
Specpoline: A speculative trampoline
To execute the test phase code (purely) speculatively, the microbenchmark uses a modified retpoline construction [3] to cause the processor to first speculatively jump to a code region that is speculatively executed and then non-speculatively jump to different code region after a pipeline flush (a “specpoline”?). Its construction is the same as a retpoline, but the emphasis is on using it to cause speculative execution of some desired code, rather than using it to suppress speculative execution. One of my earlier articles examined the behaviour of the return address stack predictor, to ensure I know how to use this technique reliably.
The function specpoline_to_measurements modifies its own return address on the stack. On processors with return address stack predictors, the final ret is always predicted to return back to the call site (test phase code), causing the processor to execute the test phase code speculatively. When the return finally resolves its return address (after reading it from the stack), the processor realizes the return was mispredicted, then flushes the pipeline and branches to the measurement code. This method allows the test phase code to reliably run speculatively, while also delaying the resolution of the specpoline’s return instruction to give the test phase code plenty of time to execute to completion.
Microbenchmark design
This code differs from the code in the Meltdown paper [1] in two major ways. First, I added several more probes (sense2, sense3, etc.) to make more detailed measurements of the behaviour of the processor, with the goal of finding out what the processor does, not just to recover privileged data. Second, instead of catching the page fault using a signal handler or with TSX transactional synchronization extensions, I (ab)use the return address stack predictor using a specpoline, which suppresses the page fault like TSX (by hiding it behind a mispredicted return), but works on many older processors that do not have TSX.
This microbenchmark is used to test the behaviour of the processor when a load is performed under varying conditions:
- Permissions: Present vs. not-present, user-accessible vs. supervisor only
- Memory types: WB (Write-back cacheable), WT (write-through cacheable), WP (write-protect cacheable), WC (uncacheable speculative write combine), UC (non-speculative uncacheable)
- Initial location of the data: L1 cached, L2 cached, not cached
- Page accessed bit: Accessed vs. not accessed
For each set of conditions, I observe the processor’s behaviour:
- None: The load did not produce a result
- Read: The load produced a result with a value from memory
- Zero: The load produced a result with value zero
- Other: There are a few other uncommon possibilities that will be discussed later
Results
| Pentium Pentium MMX |
Pentium Pro Pentium II |
Core 2 | Lynnfield | Ivy Bridge | Haswell | Atom SLM | P4 Prescott+ | K6-2 K6-2+ |
K8 | Phenom II | Bulldozer | Piledriver | Via C3 | Nano U3500 | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| L1 | Mem | L1 | Mem | L1 | Mem | L1 | Mem | L1 | Mem | L1 | Mem | L1 | Mem | L1 | Mem | L1 | Mem | L1 | Mem | L1 | Mem | L1 | Mem | L1 | Mem | L1 | Mem | L1 | Mem | ||
| Not present | None | None | PTE | PTE | Read/Zero | Zero | None | None | None | None | None | None | None | None | Read | None | None | None | None | None | None | None | None | None | None | None | None | None | Zero | Zero | |
| WB | User | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read+0 |
| WT | User | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read | Read+0 | ||||||
| WP | User | Read | Read | ||||||||||||||||||||||||||||
| WC | User | Read | Read | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | Read | Zero | ||||||||
| UC | User | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | Read | Zero | ||||||
| WB, A=0 | User | PTE | PTE | Read | Zero | Read | Zero | Read | Zero | Read | Zero | None | None | Read | None | None | None | None | None | None | None | None | None | Zero | Zero | ||||||
| WB | Supervisor | None | None | Varies | Varies | Read | Zero | Read | Zero | Read | Zero | Read | Zero | None | None | Read | None | None | None | None | None | None | None | None | None | None | None | None | None | Zero | Zero |
| WT | Supervisor | None | None | Varies | Varies | Read | Zero | Read | Zero | None | None | None | None | None | None | None | None | None | None | None | None | None | None | Zero | Zero | ||||||
| WP | Supervisor | Read | Zero | ||||||||||||||||||||||||||||
| WC | Supervisor | Read | Zero | Zero | Zero | Read | Zero | Zero | Zero | None | None | Read | None | None | None | None | None | None | None | None | None | Zero | Zero | ||||||||
| UC | Supervisor | None | None | Varies | Varies | Zero | Zero | Zero | Zero | Read | Zero | Zero | Zero | None | None | Read | None | None | None | None | None | None | None | None | None | None | None | None | None | Zero | Zero |
| WB, A=0 | Supervisor | None | None | PTE | PTE | Read | Zero | Read | Zero | Read | Zero | Read | Zero | None | None | Read | None | None | None | None | None | None | None | None | None | None | None | None | None | Zero | Zero |
Meltdown occurs when a load from supervisor-only memory (a row labelled with Supervisor) has the result Read. These cells have been outlined in blue in Table 1. Out of the processors I tested, only newer Intel processors (except Silvermont) will return data read from the L1 cache when the page is marked supervisor-only, and only when the data is already in the L1 cache. When the data is not in the L1 cache (even when in the L2), the load returns zero and does not leak information. Both Intel and VIA designs choose to return a value (and wake up dependent operations) when a permission violation occurs, but the Via Nano does not leak information because it returns zero. AMD designs choose to not wake up dependent operations.
The most commonly-used memory type is WB (write-back cacheable). WB is typically used for all memory, including user and kernel memory. The UC (uncacheable) and WC (write combine) memory types are only used for memory-mapped I/O regions. The WT (write-through) and WP (write-protect) types are rarely used, so they didn’t even appear in Linux until recently (around kernel 4.2). On older kernel versions, these types were not set up in the PAT MSR, so not all of the memory types have been tested on every system.
In all processors, reads from user-accessible memory for WB, WT, and WP memory types (cacheable, speculative loads allowed) return the loaded data, speculatively. The WC (write combine) memory type also allows (uncached) speculative loads, but it appears only the Core 2 takes advantage of this, by speculatively reading the value from WC user memory instead of not returning a result or returning zero.
When any kind of bad outcome occurs (page fault, load from a non-speculative memory type, page accessed bit = 0), none of the processors initiate an off-core L2 request to fetch the data. Where possible, I also tested the case where the victim data initially resided in L2 cache. In all cases, the load behaved identically to having the data uncached, and the victim data remained in L2 cache after the test (It was neither fetched into L1 nor evicted out to memory, showing that an off-core L2 request did not happen).
The following sections discuss some of the more detailed observations for specific processors.
Pentium, Pentium MMX
Both the Pentium and Pentium MMX are in-order processors. I was not able to get it to execute any loads after a mispredicted return. The Pentium (P54CS without MMX) doesn’t have a return address stack (RSB), so specpoline/retpoline doesn’t work. Both processors also are unable to do even a single load after a load with a page fault, so it doesn’t seem possible for these processors to leak memory information after a fault.
Oddly, on the Pentium P54CS, user-mode loads that touch not-present or supervisor-only data that is in the L1 cache will evict it. This does not happen on the Pentium MMX P55C, which leaves the inaccessible data untouched.
Pentium Pro, Pentium II
The Pentium Pro takes the “load value is a don’t-care” quite literally. For all of the forbidden loads, the load unit completes and produces a value, and that value appears to be various values taken from various parts of the processor. The value varies and can be non-deterministic. None of the returned values appear to be the memory data, so the Pentium Pro does not appear to be vulnerable to Meltdown. The recognizable values include the PTE for the load (which, at least in recent years, is itself considered privileged information), the 12th-most-recent stored value (the store queue has 12 entries), and rarely, a segment descriptor from somewhere.
The Pentium II (Klamath) has the same behaviour as the Pentium Pro.
Core 2
Unlike most other microarchitectures, the Core 2 can speculatively read the data from L1 cache for a not-present page, but only if the page frame address bits (address bits 12 and up for 4KB paging) match the cache line’s tag. In other words, the TLB lookup + cache lookup path seems to ignore the Present bit in the page table entry. If there is no match, the load completes with value zero (it’s essentially a L1 cache miss).
This potentially has implications for KPTI (kernel page table isolation). In order to prevent speculative access of a memory page on Core 2, kernel pages not only must be Not Present, its page address must also be changed/zeroed, because the speculative behaviour does not depend on the page table entry’s Present bit.
Atom Silvermont (SLM)
The Silvermont appears to execute loads in-order (Loads can be reordered relative to stores and other non-memory instructions, but loads are not reordered with other loads). A faulted load completes but does not broadcast a result or wake up its dependent operations. Any loads that follow the faulted load will execute if it is not data-dependent on the faulted load’s result, but the first load that consumes the faulted load’s result does not execute and blocks the execution of all later loads.
Pentium 4 Prescott, Presler
Wow, the Pentium 4 is weird.
On the Prescott and newer Pentium 4s, the L1 cache is virtually-indexed and virtually-tagged using the lowest 22 bits of the virtual address. Memory accesses seem to do only a cache access and, for cache hits, provides the data speculatively to dependent operations before the address translation. However, it’s not a VIVT cache, as it does a translation and aborts the memory access if a physical tag match fails. This behaviour leads to the “4M aliasing” performance problem (was “64K aliasing” in earlier Pentium 4s), where two cache lines with the same virtual address bits [21:6] (multiple of 4 MB) cannot both be in the L1 cache at the same time.
The Pentium 4 will speculatively return the value from the L1 cache whenever there is an L1 cache hit (Thus, affected by Meltdown). What’s unusual is the definition of “L1 cache hit”: a match of virtual address [21:6] with a line in the cache. This means a cache hit can occur with an unrelated line located at a multiple of 4 MB away, or a cache miss can occur even if the physical cache line is in the cache but was originally loaded using a virtual address that differs in bits [21:6].
Possibly related to this virtually-tagged madness, clflush doesn’t seem to work reliably on these microarchitectures (Doesn’t flush L1 lines? Only flushes if virtual address matches?).
K6-2, K6-2+
The AMD K6-2 and K6-2+ behaved identically. The K6 uses in-order load execution, supporting only one outstanding cache miss (hit-under-miss). This makes cache miss handling so slow that it’s challenging to find out much about its internal behaviour. I have been able to execute one speculative cache hit followed by an ALU operation and a cache miss (the standard Meltdown three-instruction sequence) when no permissions were violated. However, like other AMD processors, the load unit stalls (blocks all later loads) as soon as a load with a page fault is executed.
Another complication with the K6 family is that it uses virtually-indexed physically-tagged caches (32 KB, 2-way). Normally, this would not be an issue (e.g., the K8 is similar) because my microbenchmark uses two virtual addresses spaced far enough apart (64 KB) that the cache index is the same for both aliases, so both aliases should hit in the cache even when the virtual addresses differ. But the K6 seems to block the execution of later loads when a speculative load hits a cache line that was originally fetched through an alias, even when both the index and physical address are the same. Oddly, it doesn’t seem to show any cache miss penalty when this kind of load occurs non-speculatively.
AMD K8
On the K8, loads appear to execute in-order. A faulted load completes but does not broadcast a result or wake up its dependent operations. Any loads that follow the faulted load will execute speculatively if it is not data-dependent on the faulted load’s result, but the first load that consumes the faulted load’s result does not execute and blocks the execution of all later loads. This observation suggests that the mechanism for handling bad loads is by suppressing the broadcast of its result value (data-dependent instructions can’t execute), and not by stalling the load in the memory load unit (later loads can execute).
Reading from WT (write-through cacheable) type memory located in L1 cache seems to cause the memory to be evicted to the L2 cache. I don’t see why this would be necessary.
Phenom II
Like the K8, reading from WT type memory located in L1 cache causes the memory to be evicted to the L2 cache.
Bulldozer and Piledriver
Bulldozer and Piledriver also seems to evict data from WT type memory after a load, but evicts the data all the way to memory.
Via C3
The Via C3 is an in-order processor. It seems to be able to execute one load after a mispredicted return or after a faulting load. This is enough to determine that a faulting load does not produce a result (a data-dependent load will not execute).
Via Nano U3500
The Via Nano behaves oddly when a bad load occurs (fault or WC or UC memory type). When a bad load occurs, the load will produce a value (zero or data from the L1 cache) and broadcast it to all(?) operations except the first load immediately following the bad load. If the load immediately following a bad load is data-dependent on the bad load, then it does not execute. Thus, for the Via Nano, the test is slightly modified to insert a add eax, 0 in between the test load and the load after it, to force the first load value to travel to the integer ALU and back.
The Via Nano seems to handle regular cache misses by replay (i.e., WB or WT user-accessible data value located in memory). When this occurs, the load that consumes the cache miss value appears to execute twice, once with the value zero, and once with the correct value from memory (This is labelled as “Read+0” in Table 1). This observation is consistent with the use of a replay-like scheme to handle cache misses: The load first appears to complete with value 0, causing its dependent operations begin executing. Later, after the data is fetched from memory, the load’s dependents (or all subsequent instructions?) are replayed with the correct value and executed a second time. In my microbenchmark, the load that depends on the test load executes twice and fetches two cache lines.
Todo: Test whether this replay is runahead execution [4].
Conclusions
Meltdown can be distilled down to one microarchitectural feature: Loads that fail a permission check returning a privileged value (from the L1 cache). This allows me to use a microbenchmark to specifically test for this behaviour of load instructions and show which processors are affected by Meltdown, which are not, and why.
Out of the processors I tested, only newer Intel processors return L1 cache data when a permission check fails. But why just some microarchitectures? My guess is that Intel has just always treated the value returned by a faulting load as a don’t-care value, while some other designers have not, and have never had a reason to revisit this design choice. This is particularly evident on the early Pentium Pro (1995), which actually seems to return non-deterministic values in some cases.
I expect that the hardware cost to prevent Meltdown on future Intel processors to be near zero. There has been some speculation that Intel CPUs delay the permission check in order to improve performance, but this is highly unlikely to be true. Intel (and all other) CPUs already do checks on various bits of the page table entry (for memory type, page present bit, and page accessed bit) that affect the load value that’s returned. Fixing Meltdown would involve extending the comparison by one more bit (the Supervisor bit). AMD and Via Nano shows two alternative implementations: A faulting load can either not return a value, or return zero.
Beyond detecting Meltdown, this microbenchmark can also reveal some information on how the memory load system is designed. For example, we already observed here that the Via Nano uses some form of replay to handle cache misses, and that the AMD K8 (like many out-of-order microarchitectures from that era) executes loads in-order.
List of processors tested
| Short name | Description | CPUID family-model-stepping |
|---|---|---|
| Pentium | P54CS, 200 MHz | 5-2-12 |
| Pentium MMX | P55C, 233 MHz | 5-4-3 |
| Pentium Pro | 233 MHz, 256 KB L2 cache | 6-1-9 |
| Pentium II | Klamath, 233 MHz | 6-3-4 |
| Core 2 | Core 2 Duo E4300 Pentium Dual-Core E5200 Core 2 Quad Q9550 |
6-15-2 6-23-6 6-23-10 |
| Lynnfield | Core i7-860 | 6-30-5 |
| Ivy Bridge | Core i5-3570K | 6-58-9 |
| Haswell | Core i7-4770K | 6-60-3 |
| Atom SLM | Celeron J1900 (Silvermont) | 6-55-3 |
| P4 Prescott+ | Pentium 4 521 (Prescott) Pentium D 820 (Smithfield) Pentium D 915 (Presler) |
15-4-7 15-4-7 15-6-4 |
| K6-2 | K6-2 (CXT) 0.25µm 500 MHz | 5-8-12 |
| K6-2+ | K6-2+ 0.18µm 570 MHz | 5-13-4 |
| K8 | Sempron 2100+ 1 GHz (65nm) | 15-108-2 |
| Phenom II | Phenom II X6 1090T | 16-10-0 |
| Bulldozer | FX-8120 | 21-1-2 |
| Piledriver | FX-8320 | 21-2-0 |
| Via C3 | Samuel 2 | 6-7-3 |
| Nano U3500 | VIA (Centaur) Nano U3500 | 6-15-8 |
Source Code
References
Cite
- H. Wong, The Microarchitecture Behind Meltdown, May, 2018. [Online]. Available: http://blog.stuffedcow.net/2018/05/meltdown-microarchitecture/
[Bibtex]@misc{this, author={Henry Wong}, title={The Microarchitecture Behind Meltdown}, month={may}, year=2018, url={http://blog.stuffedcow.net/2018/05/meltdown-microarchitecture/} }
Hi
thanks for your interesting post,
in this blog you told that “My microbenchmark begins by allocating one memory page, then creates two virtual address aliases pointing to it. This means that the same memory is accessible via two different virtual addresses.”. i could not understand how you could assign two different virtual address to same physical memory location, could you please describe how you did that?
and also you told that “One of the virtual pages (which we’ll call the “setup” pointer) is set to allow access from user mode. … The second virtual page (“test” pointer) is set to varying permissions and memory type settings”. also i can not understand could you change permission bit of a virtual page (“test” pointer) in virtual page table of your programme. again could you please describe this to me?
i asked those questions in StackOverflow and etc but i could not find the solution, so please describe them to me.
Thanks
I assume you are familiar with paging (address translation), and how x86 page tables work?
Virtual addresses are translated into physical addresses by walking the page tables. The page tables hold the address of the physical page and the permission bits. There is no restriction on this mapping. Any virtual page can map to any physical page, with any permissions. You just need to edit the page tables to contain the right page table entry bits. For a description of what goes in the page tables and the meaning of each bit, you’ll need to look at some x86 documentation (look for address translation or CR3), or the equivalent system-mode documentation for the CPU instruction set you’re using.
So now that you know what to do, all that’s left is how. Unfortunately, the OS manages page tables for you and makes it impossible for you to write (or even read) the page tables outside of kernel mode. The method I used was to write a Linux kernel module that gave me the value of CR3 (which tells me where the page tables for the current process are), then directly manipulated the page tables (in physical address space) using /dev/mem.
I used the same technique in an earlier experiment. The source code for the kernel module is there too: http://blog.stuffedcow.net/2015/08/pagewalk-coherence/
Thank you, it was very helpful.
Hi and thanks for the interesting content.
I have noticed that you have a huge knowledge in the computer area and CPU internals. I have a question and I would deeply appreciate it if you kindly answer it.
In this post, you have used Return Stack Buffer to implement the meltdown and I guess that this can also happen with miss predicting PatternHistoryTable (PHT) and Spectre-V1 gadget. as you surely know spectre-v1 gadget is something like this:
if(index < un_cached_value) { /* do some bad thing*/ }
my question is, can we expect using an uninitialized memory pointer(which will cause major page fault to load the data from the disk) to extend the speculative execution window?
as I can see access time to variable in different situation is something like this:
cache hit: around 100 clock cycle
cache miss: around 300 clock cycle
major page fault: around 20000 clock cycle
and the second question is if we use major page fault to extend the speculative execution window could we expect that CPU loads the kernel data from the memory as it has more time to load it?
Thanks again
Just to be more precise, with:
“can we expect using an uninitialized memory pointer(which will cause major page fault to load the data from the disk) to extend the speculative execution window?”
I mean
“can we expect using an uninitialized memory pointer(which will cause major page fault to load the data from the disk) instead of “un_cached_value” extends the speculative execution window?”
No, I don’t think that would work. A page fault is a fault, which means the CPU has to abort what it is doing and branch to a fault handler. The CPU may speculatively execute past a load, but if that load has a page fault (page not present?), it has to squash the speculative path it was executing and jump to the page fault handler. Faults are (usually?) not speculative. They’re handled when the load instruction retires.
The 20000 cycles you see for a page fault is not a stall for that long. It includes the time spent executing the page fault handler (which may even context switch!) and the time to return back to the instruction that caused the fault to retry it.
Also, even if you do find a method to stall the CPU for 20000 cycles, the size of the speculation window is limited by the ROB size (usually a few hundred entries or less). Once the ROB is full, it can’t speculate any further ahead even if there were time to do so.
Thank you so much,
I have another question and I would be grateful if you answer it. I think that during this access CPU will encounter with a TLB miss (as the virtual to physical translation is not exists in this table) and it needs to follow page table(which it also need some memory access) to translate virtual address to physical address and then it will encounter with a page fault.
could you please tell me what happens during the TLB miss? CPU will execute the speculative path during this time? or it will interrupt it?.
and if CPU executes the speculative path, TLB miss could be used to extend the speculative window?
excuse me for too many questions
Of course, until ROB size allows us.
TLB miss handling on architectures most relevant today (x86, ARM) are handled in hardware. Some architectures cause a fault on a TLB miss and let the OS walk the page tables.(https://en.wikipedia.org/wiki/Translation_lookaside_buffer#TLB-miss_handling). CPUs that handle TLB misses in hardware will usually speculatively execute past a TLB miss.
So yes, a TLB miss can be used to cause a longer stall, giving more time for instructions after it to be fetched/executed. If TLB misses are handled speculatively, it just looks like a slower cache miss. In fact, your “300 cycles” for the cache miss probably already includes some TLB miss time (a memory access without TLB misses is usually not that slow). The L2 TLB on recent Intel/AMD CPUs are 1-2K entries, so you’re likely to get a L2 TLB miss if your cache misses were caused by random accesses to an array larger than ~4-8MB (assuming 4KB page size).
Thank you so much.
Excuse me, I have another question. as indicated in the results, we can map a memory location(with user privilege) to the cache during speculative execution in some processors, either it existed in the cache or in memory.
I think that for this we need at least four instructions to be done in the speculative execution part.
(1). loading secret from memory to a register –>
(2). shifting it 6bit to left(*64 where 64 is cache line size) –>
(3). adding this with an oracle base address –>
(4). and again access to the calculated memory location (this memory access at least should be initiated)
step 1 to 4 is assembly of “junk &= oracle[secret * 64]” instruction which can be used to map secret to cache.
loading the return address from the memory should be done with step (1) and return address from software stack should be available before step (2), and consequently, CPU should flush the pipeline.
Now my question is, Why cpu execute instructions in step (2,3,4) speculatively?
Excuse me for too many questions, again (and probably simple questions:)
thanks
If you’re assuming an out-of-order CPU that has branch prediction, why would it not speculatively execute instructions #1 to #4? The sequence (1,2,3,4) may need to execute in-order due to data dependencies between them, but what stops the entire sequence from being executed?
Your assumption that the correct return address is available before step #2 isn’t true. The “few long latency operations” right after
specpoline_to_measurements:is intended to delay the availability of the return address.Yes, I thought that data dependency between (1,2,3,4) should stop the out of order execution.
because both of the return address and the secret should be loaded from the DRAM.
anyway, thank you. it was so helpful